Blog Details
| Blog Title: | K-MEANS CLUSTERING IN PYTHON |
|---|---|
| Blogger: | pdudhnikar@gmail.com |
| Image: | View |
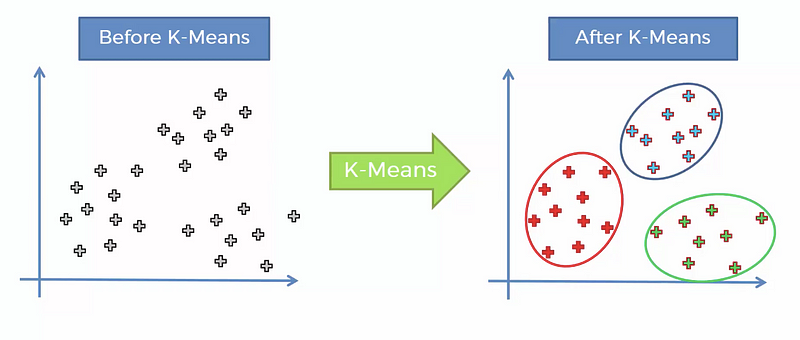
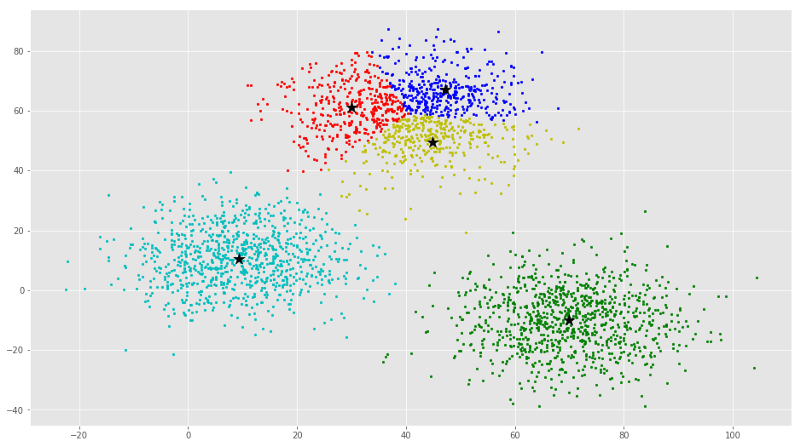
| Content: | The k-means clustering is a method of vector quantization, originally from signal processing, that is popular for cluster analysis in data mining. k-means clustering aims to partition n observations into k clusters in which each observation belongs to the cluster with the nearest mean, serving as a prototype of the cluster. This results in a partitioning of the data space into Voronoi cells. The problem is computationally difficult (NP-hard); however, there are efficient heuristic algorithms that are commonly employed and converge quickly to a local optimum. These are usually similar to the expectation-maximization algorithm for mixtures of Gaussian distributions via an iterative refinement approach employed by both k-means and Gaussian mixture modeling. Additionally, they both use cluster centers to model the data; however, k-means clustering tends to find clusters of comparable spatial extent, while the expectation-maximization mechanism allows clusters to have different shapes. K- means clustering allows you to cluster our data, and is a good tool when we need to discover clusters you wouldnt know yourself, and that is why this algorithm belongs to the unsupervised learning category. To give a practical example here we have a scatterplot, and lets imagine that we 2 variables in our dataset:
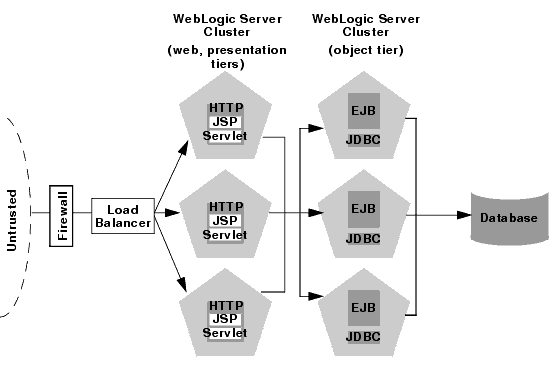
Architecture of cluster In cluster architecture, requests or parts of the user requests are divided among two or more computer systems, such that a single user request is handled and delivered by two or more than two nodes (computer systems). The benefit is unquestionably the ability of load balancing and high-availability. How? If one node fails, the request is handled by another node. Hence, there are less or negligible chances of complete system failures.
The benefits of the Recommended Basic Architecture are: Because a single cluster hosts static HTTP pages, servlets, and EJBs, you can configure the entire Web application and deploy/undeploy objects using the WebLogic Server Console. You do not need to maintain a separate bank of Web servers (and configure WebLogic Server proxy plug-ins) to benefit from clustered servlets. Using load balancing hardware directly in front of the WebLogic Server cluster enables you to use advanced load balancing policies for accessing both HTML and servlet content. For example, you can configure your load balancer to detect current server loads and direct client requests appropriately. Placing a firewall in front of your load balancing hardware enables you to set up a De-Militarized Zone (DMZ) for your web application using minimal firewall policies.
|
{kind=link}