Scikit Learn

In this blog you will get an overview of the scikit-learn library and useful references of where you can learn more.
Where did it come from?
Scikit-learn was initially developed by David Cournapeau as a Google summer of code project in 2007.
Later Matthieu Brucher joined the project and started to use it as apart of his thesis work. In 2010 INRIA got involved and the first public release (v0.1 beta) was published in late January 2010.
What is scikit-learn?
Scikit-learn provides a range of supervised and unsupervised learning algorithms via a consistent interface in Python.
It is licensed under a permissive simplified BSD license and is distributed under many Linux distributions, encouraging academic and commercial use.
The library is built upon the SciPy (Scientific Python) that must be installed before you can use scikit-learn. This stack that includes:
- NumPy: Base n-dimensional array package
- SciPy: Fundamental library for scientific computing
- Matplotlib: Comprehensive 2D/3D plotting
- IPython: Enhanced interactive console
- Sympy: Symbolic mathematics
- Pandas: Data structures and analysis
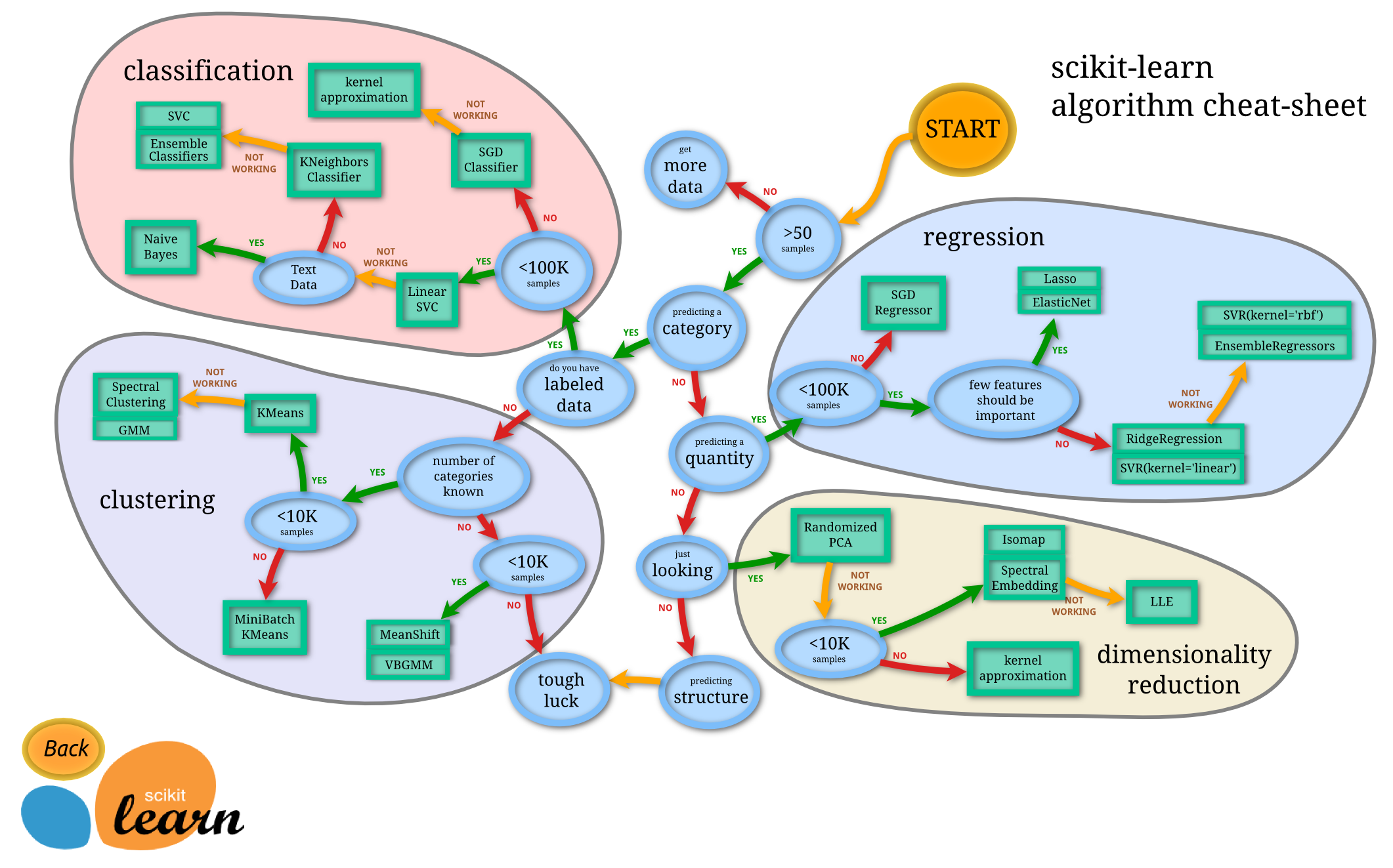
What are the features?
The library is focused on modeling data. It is not focused on loading, manipulating and summarizing data. For these features, refer to NumPy and Pandas.
Some popular groups of models provided by scikit-learn include:
- Clustering: for grouping unlabeled data such as KMeans.
- Cross Validation: for estimating the performance of supervised models on unseen data.
- Datasets: for test datasets and for generating datasets with specific properties for investigating model behavior.
- Dimensionality Reduction: for reducing the number of attributes in data for summarization, visualization and feature selection such as Principal component analysis.
- Ensemble methods: for combining the predictions of multiple supervised models.
- Feature extraction: for defining attributes in image and text data.
- Feature selection: for identifying meaningful attributes from which to create supervised models.
- Parameter Tuning: for getting the most out of supervised models.
- Manifold Learning: For summarizing and depicting complex multi-dimensional data.
- Supervised Models: a vast array not limited to generalized linear models, discriminate analysis, naive bayes, lazy methods, neural networks, support vector machines and decision trees.
