Web scraping
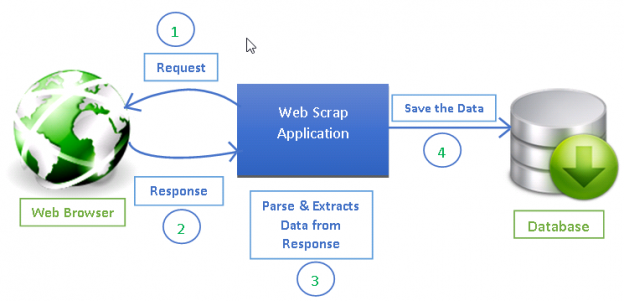
Scrapy overview :
Web scraping has become an effective way of extracting information from the web for decision making and analysis. It has become an essential part of the data science toolkit. Data scientists should know how to gather data from web pages and store that data in different formats for further analysis.
Any web page you see on the internet can be crawled for information and anything visible on a web page can be extracted . Every web page has its own structure and web elements that because of which you need to write your web crawlers/spiders according to the web page being extracted.
Scrapy uses spiders, which are self-contained crawlers that are given a set of instructions. In Scrapy it is easier to build and scale large crawling projects by allowing developers to reuse their code.
Scrapy Vs. BeautifulSoup :
Scrapy is a Python framework for web scraping that provides a complete package for developers without worrying about maintaining code.
Beautiful Soup is also widely used for web scraping. It is a Python package for parsing HTML and XML documents and extract data from them. It is available for Python 2.6+ and Python 3.
Here are some differences between them in a nutshell:
Scrapy :-
1) Scrapy is the complete package for downloading web pages, processing them and save it in files and databases
2) Scrapy is a powerhouse for web scraping and offers a lot of ways to scrape a web page. It requires more time to learn and understand how Scrapy works but once learned, eases the process of making web crawlers and running them from just one line of command. Becoming an expert in Scrapy might take some practice and time to learn all functionalities.
3) Scrapy can get big jobs done very easily. It can crawl a group of URLs in no more than a minute depending on the size of the group and does it very smoothly as it uses Twisterwhich works asynchronously(non-blocking) for concurrency.
4) Scrapy provides Item pipelines that allow you to write functions in your spider that can process your data such as validating data, removing data and saving data to a database. It provides spider Contracts to test your spiders and allows you to create generic and deep crawlers as well. It allows you to manage a lot of variables such as retries, redirection and so on.
BeautifulSoup :-
1) BeautifulSoup is basically an HTML and XML parser and requires additional libraries such as requests, urlib2 to open URLs and store the result.
2) BeautifulSoup is relatively easy to understand for newbies in programming and can get smaller tasks done in no time.
3) BeautifulSoup is used for simple scraping jobs with efficiency. It is slower than Scrapy if you do not use multiprocessing.
4) If the project does not require much logic, BeautifulSoup is good for the job, but if you require much customization such as proxys, managing cookies, and data pipelines, Scrapy is the best option.
Why Use Scrapy?
-
It is easier to build and scale large crawling projects.
-
It has a built-in mechanism called Selectors, for extracting the data from websites.
-
It handles the requests asynchronously and it is fast.
-
It automatically adjusts crawling speed using Auto-throttling mechanism.
-
Ensures developer accessibility.
Features of Scrapy
-
Scrapy is an open source and free to use web crawling framework.
-
Scrapy generates feed exports in formats such as JSON, CSV, and XML.
-
Scrapy has built-in support for selecting and extracting data from sources either by XPath or CSS expressions.
-
Scrapy based on crawler, allows extracting data from the web pages automatically.
Advantages
-
Scrapy is easily extensible, fast, and powerful.
-
It is a cross-platform application framework (Windows, Linux, Mac OS and BSD).
-
Scrapy requests are scheduled and processed asynchronously.
-
Scrapy comes with built-in service called Scrapyd which allows to upload projects and control spiders using JSON web service.
-
It is possible to scrap any website, though that website does not have API for raw data access.
